I failed at maintaining at least one post per month, a lot of distractions are abound! I've been trudging away nonetheless. The project is at a point where I am leaping from one milestone to the next, some days being spent refactoring smaller support code and/or adding functionality to various support systems.
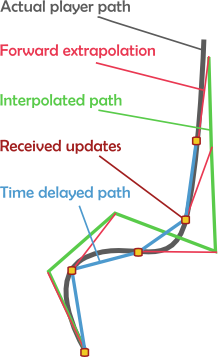
I have just added some code for dealing with quaternions for representing object orientations, as euler angles will just not suffice for the physics interactivity I am striving for. To represent rotational velocities I have also added code to handle axis-angle representations, because quaternions inherently limit rotation to 180 degrees, or in the case of rotational velocity 30 RPM.
One feature of the engine that I was looking to implement is procedural model scripting. The goal here is to allow a user to easily script a game 'model'. A model consists of vertices defined for the three basic primitives which are points, lines, and triangles. Each of these vertices have a RGBA value for rendering a color.
The primary advantage of having scripted models are that anybody can edit them, without learning modeling software. All you need is a text editor - which I aim to build into the engine in some capacity (after making a release) to eliminate the need for alt-tab madness. Scripting a model is a matter of cleverly putting together a series of commands that rotate and translate to reach the desired position of each vertex for the desired primitive type.
Another advantage of using procedurally scripted models is that game server admins can run games with their own custom models, which are quickly and easily transferred over the network to player clients. Clients can then generate the actual models by executing the procedures defined therein. This is huge because it is another goal to allow server admins to run entirely customized games without requiring players to download and install anything manually.
 |
| A script for a 'sprial tree' model, demonstrating the use of nested loops. |
Another feature of the modeling system is the ability to push/pop the current matrix and loop counters. This allows for recursive modeling of hierarchical things like trees, plants, and other fractal shapes.
 |
| Some spiral trees, and dynamic mesh player model. |
Along with scripting individual procedural models I have implemented an animation system that I devised a long while back. This was yet another chance to embark on a journey that strayed from the norm. I love skeletal animation, and inverse-kinematics for making a skeletal model interact seamlessly with the game world, but I do not love the mind-numbing rote-implementation of features that all the creative work has already been done around. To me, programming is about problem solving, the deeper and more abstract the problem, the more rewarding it is to me. Infact, making a game all by itself isn't that rewarding to me (earning a living is good, though). It's the process and the challenges of making something involved that I find rewarding, and I wish more programmers felt the same. At any rate...
Conventional animation systems involve manipulating a mesh model using a virtual skeleton with virtual joints. Keyframed animation is stored as angles for each joint, and is easily to interpolate for smooth animation between keyframes. Getting any keyframed animation to smoothly and seamlessly interact with the world and external forces like wind, inertia, gravity, collisions, etc.. is tricky in and of itself. It's a challenging problem. Some games only let the model/skeleton interact when the character is dead, allowing the body to flop around in response to external forces. This is known as 'rag-doll' physics. There are various solutions now for handling these sorts of things, both for animating and dead character models. There's even one solution that dynamically generates/modifies keyframed animations for things like walking, so that it looks as though the character is actually negotiating bumpy terrain with strategic footstep positions.
I did not want to plug in a solution, and I did not want to pursue a solution that was too involved. This is where the dynamesh comes in. Dynamesh is just a abbreviation of the term 'dynamic mesh'. A dynamic mesh is just a spring mesh, where vertices are referred to as 'nodes' and the edges connecting two 'nodes' are called 'links'. This is a simple system where each node is given a size (zero is valid) and a mass, and each link is given a rigidity value that dictates how will it retains it should retain its length.
This system is simple enough to simulate. It consists of two parts - a particle simulation for the nodes themselves, and an iterative link-constraint system that pushes and pulls the nodes of each link in an attempt to 'settle' the mesh.
So far, I have determined three uses for this system:
The first use is entity collision volume representation. Along with using spheres, capsules, axis-aligned bounding-boxes, and the like, it's nice to allow for more detailed collision hulls for bigger more complicated entities.
The second use of the dynamesh system, which operates in tandem with the first use, is rigid body physics. It is an automatic feature of this system to allow all the nodes to be in any orientation, with no real 'orientation' at any point in the code. Discerning anything like an 'orientation' involves examining the relationship between node positions, and comparing it to the original default orientation. This isn't too hard or expensive to do. Entities can use a dynamic mesh as not just their collision hull, but also to innately handle collision response and resolution. This enables highly interactive entity physics behaviors.
The third use is animation. Not only can you define a dynamesh that is rigid, but you can define one for a character, or a vehicle, or anything with moving parts. With one pair of nodes you can have a ball and socket type joint. With three nodes you can have a hinge. Through clever use of nodes and links you can create just about anything, and the neat thing is that simulating the nodes as particles that are affected by external forces and collisions allows for highly dynamic interactivity automatically, without any special-case code at all.
In this case I am using dynameshes for character animation, while allowing for an entity to have one scripted procedural model that is permanently attached to them, as well as one dynamesh, which can have models attached to its links. This makes it simple enough to define a character dynamesh.
Keyframed animation is a matter of storing node 'goals' for each keyframe, and pushing those nodes toward their goals when a specific animation is playing. In this case I am procedurally generating running animations through some simple manipulation of foot/knee nodes. Dynameshes must define anchor nodes, which are used to fix the mesh to the entity using them. Entities are essentially dragging the mesh around the world, unless the entity type specifies that it is to assume the physical state of the dynamesh, then the anchor nodes are used to dictate an entity's position/orientation.
Links:
Lightweight Procedural Animation ... by Ian Horswill
NeHe Productions: Rope Physics
QUELSOLAAR.COM: Confuce - Procedural Character Animator
Conventional animation systems involve manipulating a mesh model using a virtual skeleton with virtual joints. Keyframed animation is stored as angles for each joint, and is easily to interpolate for smooth animation between keyframes. Getting any keyframed animation to smoothly and seamlessly interact with the world and external forces like wind, inertia, gravity, collisions, etc.. is tricky in and of itself. It's a challenging problem. Some games only let the model/skeleton interact when the character is dead, allowing the body to flop around in response to external forces. This is known as 'rag-doll' physics. There are various solutions now for handling these sorts of things, both for animating and dead character models. There's even one solution that dynamically generates/modifies keyframed animations for things like walking, so that it looks as though the character is actually negotiating bumpy terrain with strategic footstep positions.
I did not want to plug in a solution, and I did not want to pursue a solution that was too involved. This is where the dynamesh comes in. Dynamesh is just a abbreviation of the term 'dynamic mesh'. A dynamic mesh is just a spring mesh, where vertices are referred to as 'nodes' and the edges connecting two 'nodes' are called 'links'. This is a simple system where each node is given a size (zero is valid) and a mass, and each link is given a rigidity value that dictates how will it retains it should retain its length.
This system is simple enough to simulate. It consists of two parts - a particle simulation for the nodes themselves, and an iterative link-constraint system that pushes and pulls the nodes of each link in an attempt to 'settle' the mesh.
So far, I have determined three uses for this system:
The first use is entity collision volume representation. Along with using spheres, capsules, axis-aligned bounding-boxes, and the like, it's nice to allow for more detailed collision hulls for bigger more complicated entities.
The second use of the dynamesh system, which operates in tandem with the first use, is rigid body physics. It is an automatic feature of this system to allow all the nodes to be in any orientation, with no real 'orientation' at any point in the code. Discerning anything like an 'orientation' involves examining the relationship between node positions, and comparing it to the original default orientation. This isn't too hard or expensive to do. Entities can use a dynamic mesh as not just their collision hull, but also to innately handle collision response and resolution. This enables highly interactive entity physics behaviors.
The third use is animation. Not only can you define a dynamesh that is rigid, but you can define one for a character, or a vehicle, or anything with moving parts. With one pair of nodes you can have a ball and socket type joint. With three nodes you can have a hinge. Through clever use of nodes and links you can create just about anything, and the neat thing is that simulating the nodes as particles that are affected by external forces and collisions allows for highly dynamic interactivity automatically, without any special-case code at all.
In this case I am using dynameshes for character animation, while allowing for an entity to have one scripted procedural model that is permanently attached to them, as well as one dynamesh, which can have models attached to its links. This makes it simple enough to define a character dynamesh.
Keyframed animation is a matter of storing node 'goals' for each keyframe, and pushing those nodes toward their goals when a specific animation is playing. In this case I am procedurally generating running animations through some simple manipulation of foot/knee nodes. Dynameshes must define anchor nodes, which are used to fix the mesh to the entity using them. Entities are essentially dragging the mesh around the world, unless the entity type specifies that it is to assume the physical state of the dynamesh, then the anchor nodes are used to dictate an entity's position/orientation.
Links:
Lightweight Procedural Animation ... by Ian Horswill
NeHe Productions: Rope Physics
QUELSOLAAR.COM: Confuce - Procedural Character Animator