Distributing the game state among multiple machines can be tricky business, depending on the complexity of your game state itself. Most games treat the game state as an array of entities, sometimes indexed using some sort of a scene graph or other hierarchical organization. At the end of the day, though, it's just a list.
To make designing the game more flexible (what with scripting, etc) usually these entities are represented as merely an entity index, and a chunk of data associated with that entity. This data 'blob' is then structured into meaningful values through the scripting system, which divides it up into entity state variables like origin, velocity, model index, etc.
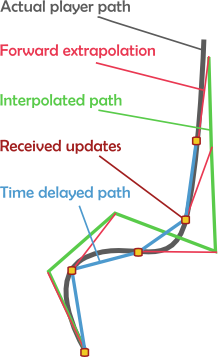
On the networking side of things the engine discerns what state changes have been made to each entity that are relevant to the machine on the other end of the connection. Typically this consists of the server trying to figure out what information is relevant to each client about all the entities in the game, based on what the server knows the client has received so far, and what the client needs to know for its perspective of the game state.
This entails a complex system of backing up copies of the game state to generate a delta-compressed update unique to each client's situation, based on what the client has acknowledged having received as far as the game state is concerned. Fortunately, things are much simpler for the client, only being required to update the server concerning the player's activities in a much simpler scope.
The system I've been developing the past few days simplifies things, for the most part. It could also potentially simplify peer-to-peer type games, as an emergent property of its design. But for now I'm focusing on utilizing a server for simulating most of the game state, while allowing clients to submit their own simulation states. The goal, for simplicity's sake, is to utilize the same system on both ends for dealing with generating and sharing the game state.
This requires a system that works virtually like two servers talking to one-another. The only difference is that the client has a player manipulating the game state that it's responsible for relaying to the server, which in turn relays them to other clients.
One strategy for simplifying the description of entity types, while simultaneously simplifying serialization of entity states for network transmission, is to utilize entity type templates. Instead of having a scripting language that describes (in some sort of VM-executed code) setting the state of an entity, one variable at a time, why not just have static entities that are essentially copied to real entities based on specific triggers or events occuring?
Then, all that's needed to be transferred over the network when an entity's non-continuous state evolves (eg: entity flags, boolean states, model index, physics type, etc) is an ID value for the specific entity template that the entity should become. This eliminates the need to submit any specific entity properties outside of the continuous state (like origin, velocity, etc). The server could send these templates to clients, so that servers can be running customized games.
Utilizing an event-system, for things like player chat messages, player actions (jump, shoot, kill), entities changing their type/template, etc. allows the game state to be divided into discrete 'frames' that are not based on units of time, but units of actual state change. Each machine, upon generating an event, both executes the event and queues it to be distributed to remote systems.
Clients distribute their locally-generated events to the server (through a Quake3 style re-send until acknowledgement received method) which execute the events, and queue them to be further distributed to all clients. One global queue can be used on the server, in a circular buffer, and each client connected will continuously provide the server with acknowledgement of the last received event.
Right now I am implementing the events system which consists of an event execution mechanism (giant switch/case) and data parsing. Data comes in as a simple void* pointer, which is either forwarded from a network-parsed event, or from wrapper functions which allow engine code to invoke specific events with actual variable parameters by lumping them into data identical to what can be found in a network event.
Right now I am implementing the events system which consists of an event execution mechanism (giant switch/case) and data parsing. Data comes in as a simple void* pointer, which is either forwarded from a network-parsed event, or from wrapper functions which allow engine code to invoke specific events with actual variable parameters by lumping them into data identical to what can be found in a network event.
Links of interest: